R: Um guia prático
Fernando Meireles
Universidade Federal de Minas Gerais
1 Como usar
Este guia não é um curso de R, nem um tutorial ou um livro sobre. Ele é uma referência prática sobre a linguagem por detrás do R - o que significa que o foco dele é no código, na adaptação de exemplos. Ainda assim, este material não oferece uma introdução ampla às potencilialidades deste ambiente de programação, apenas a uma parte importante dela: o conteúdo exposto aqui cobre deste o mais básico, que é como trabalhar no console, até análises mais simples. Em outras palavras, o conteúdo cobre o mínimo básico, os fundamentos, para quem quer trabalhar seriamente com o R.
Por esta razão, o conteúdo do guia provavelmente será mais útil para iniciantes, ainda que também sirva para usuários(as) com nível intermediário aprenderem algumas coisas novas (a verdade é que todo mundo está sempre aprendendo quando o assunto é programação). De qualquer modo, o conteúdo do guia está todo separado em seções e subseções - o menu à esquerda permite visualizar e navegar por elas. Caso tenha algo específico em mente, pule para a parte que te interessar.
Para usar o guia, portanto, navegue pelo conteúdo, tente entender cada código, reproduzindo e adaptando exemplos, e siga pelas seções. O material avança rapidamente, o que pode tornar necessário ir e voltar várias vezes no texto. Caso tenha dúvidas, use o bom e velho Ctrl+f para procurar um tópico específico. Outra dica: use o www.google.com para procurar coisas que não encontrar aqui; na esmagadora maioria das vezes, ele terá uma resposta para te oferecer.
1.1 Instruções gerais de leitura do código
- Tudo o que estiver em caixa cinza, com texto destacado por cores, é código e pode ser executado (copie e cole no
R); - Tudo o que estiver em caixa branca, sem destaque no texto, é output do
R; - Alguns códigos dependem de códigos anteriores; caso encontre algum erro ao rodar um código de exemplo, tente voltar atrás e rodar o código anterior.
1.2 Instruções sobre o guia
- Tente reproduzir cada exemplo e procure entender o que cada código produz;
- Teste variações dos exemplos, mude parâmetros, valores, etc.;
- Combine materiais de diferentes seções;
- Na maioria das vezes, explicações não ajudam a entender um código; aprender por exemplos é muito mais fácil; caso tenha dúvidas, repita os códigos.
1.3 Requisitos
Não é necessário nada além de ter uma versão do R instalada no computador para reproduzir e testar o código disponível nos exemplos. Caso não disponha de uma, tente usar o R online pelo site:
2 Básico
2.1 O console
Abrindo diretamente o R, a primeira coisa que vemos nele é um console - que nada mais é do que uma caixa de texto onde colocamos nosso código. Experimente digitar, por exemplo, 2 ali.
2## [1] 2O R reproduzirá o 2 digitado seguido de # e [], geralmente com algum número dentro. No primeiro caso, # indica um comentário: tudo o que vem sucedido de # o R não executará.
# Isto é um comentário
# O 2, abaixo, não é um comentário
2## [1] 2# O 2, abaixo, é um comentário
# 2O R também serve como calculadora: basta usar operadores matemáticos e números. Aqui vão alguns exemplos (tente outros).
2 + 2 # adição## [1] 42 - 2 # subtração## [1] 02 / 2 # divisão## [1] 12 * 2 # multiplicação## [1] 42^2 # 2 ao quadrado## [1] 42^3 # 2 ao cubo## [1] 83 %/% 2 # divisão sem resto## [1] 13 %% 2 # resto da divisão## [1] 12.2 Funções
O R também possui muitas funções - parte da potencialidade dele vem daí, aliás. Funções servem para realizar ações no R, como calcular a raiz quadrada de um número.
# a funcao sqrt() retorna a raiz quadrada de um número
sqrt(4) # raiz quadrado de 4## [1] 2Outros exemplos de funções.
log(4) # logaritmo natural de 4## [1] 1.386294log10(4) # logaritmo base 10 de 4## [1] 0.60206sum(2, 2) # soma dois ou mais números## [1] 42.3 Criando objeto
Podemos armazenar objetos no R com o operador <- (menor seguido de hífen). Basicamente, ele diz ao R para armazenar um valor num objeto para podermos acessá-lo posteriormente. Podemos salvar o número 2 num objeto x.
x <- 2E depois usá-lo diretamente para realizar outras operações.
x## [1] 2x + 1## [1] 3x / 2## [1] 1x^2## [1] 4Também podemos armazenar texto num objeto.
texto <- "texto"
texto## [1] "texto"x <- "outro texto"
x## [1] "outro texto"A função print() nos permite visualizar o conteúdo armazenado num objeto (digitar o nome dele no console e executar é o equivalente disso, mas print pode ser útil em algumas situações).
print(texto)## [1] "texto"print(x)## [1] "outro texto"2.4 Classes
No R, cada tipo de informação possui uma classe. Números são numeric ou integer (para números inteiros); texto é character (também pode ser factor). Também existem valores lógicos (TRUE ou FALSE, ou T e F, respectivamente), complexos, etc. Vamos ver os mais comuns.
class("a") # "a" é character## [1] "character"is.character("a") # "a" é character## [1] TRUEclass(2) # é numeric## [1] "numeric"is.numeric(2) # é numeric## [1] TRUEclass(2L) # 2L (o L força o número a ficar inteiro) é integer## [1] "integer"is.integer(2L) # 2L é integer## [1] TRUEclass(TRUE) # TRUE é logical## [1] "logical"is.logical(TRUE) # TRUE é logical## [1] TRUEValores lógicos são úteis para fazer testes relacionais (comparações) com valores. Podemos verificar se 2 é maior que 1, por exemplo.
2 > 1## [1] TRUEOu se 2 é maior que 3.
2 > 3## [1] FALSEOutros operadores relacionais úteis.
2 > 1 # maior## [1] TRUE2 < 1 # menor## [1] FALSE2 >= 1 # maior ou igual## [1] TRUE2 <= 1 # menor ou igual## [1] FALSE2 == 1 # igual (note que existem dois '=' aqui)## [1] FALSE2 != 1 # diferente## [1] TRUE!TRUE # inverso (não é bem um operador, mas é útil para inverter o resultado de um operador)## [1] FALSE2.5 Recomendações
Podemos criar objetos e realizar operações no R de forma simples, como vimos. No entanto, algumas coisas devem ser evitadas quando escrevemos nosso código, seja para evitar erros ou para facilitar a compreensão.
A recomendação mais básica neste sentido é: evite criar objetos com nomes que comecem com números, caracteres especiais ou nomes de funções. Algumas destas coisas produzirão erros imediatos; outras, podem complicar códigos inteiros. Alguns exemplos.
# Exemplos de nomes de objetos que produzem erros
2x <- 1
_x <- 1
&x <- 1
# Exemplos de nomes de objetos que não produzem erros imediatos
class <- 1
print <- 1## Error: <text>:2:2: unexpected symbol
## 1: # Exemplos de nomes de objetos que produzem erros
## 2: 2x
## ^Também note que o R é case sensitive, o que significa que A não é a mesma coisa que a.
A <- 1
print(a)## Error in print(a): objeto 'a' não encontradoSempre que criar um objeto armazenando texto, não esqueça das aspas (outra forma de cometer erros no R bastante comum).
x <- texto
x <- "texto"
x## [1] "texto"Por fim, sempre que abrir parênteses, não esqueça de fechá-los (caso contrário, aparecerá um + no console, indicando que o R espera mais conteúdo). Estas e outras recomendações comuns para evitar erros podem ser vistas aqui (em inglês).
2.6 Estilo
Isto não é mandatório, mas algumas noções de estilo - i.e., de como organizar o código - nos ajudam a compreender e partilhar códigos, tanto nossos quanto os de outras pessoas. Resumidamente, as principais considerações aqui são:
- Use espaços entre objetos, operadores e chamadas a funções;
- Use quebra de linhas para separar blocos de códigos;
- Sempre que possível, crie objetos apenas com letras minúsculas;
- Se precisar separar o nome de um objeto, use
_(underscore); - Prefira nomes curtos para objetos;
- Prefira o atribuidor
<-a=(eles fazem a mesma coisa).
Exemplos.
x<-1 # Ruim
x <- 1 # OK
x+x+x+x # Ruim
x + x + x + x # OK
print (x) # Ruim
print(x) # OK
x = 1 # Ruim
x <- 1 # OK
OBJETO <- 1 # Ruim
objeto <- 1 # OK
meu.objeto <- 1 # Ruim
meu_objeto <- 1 # OK
objeto_com_nome_excessivamente_grande <- 1 # Ruim
objeto <- 1 # OKUm guia completo de estilo, em inglês, pode ser encontrado neste link.
3 Vetores
3.1 Vetores
Podemos armazenar mais de um valor num objeto: para isto, criamos um vetor. Vetores armazenam uma sequência de valores em ordem, e cada um fica salvo num elemento do vetor. Usamos a função c para criar um vetor.
x <- c(1, 2, 3) # vetor com três elementos numéricos
y <- c("a", "b", "c") # vetor com três elementos de textoPodemos realizar operações com vetores da mesma forma que com valores únicos (na verdade, valores únicos são vetores com apenas um elemento). Tente outras além destas.
x <- c(1, 2, 3, 4, 5)
x + 1## [1] 2 3 4 5 6x - 1## [1] 0 1 2 3 4x^2## [1] 1 4 9 16 25c(1, 2, 3) + c(1, 2, 3)## [1] 2 4 6Outras formas de criar vetores.
seq(1, 10, by = 1) # cria um vetor de 1 a 10## [1] 1 2 3 4 5 6 7 8 9 10seq(1, 10, by = 0.5) # vetor de 1 a 10 com intervalos de 0.5## [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5
## [15] 8.0 8.5 9.0 9.5 10.0rep(1, 10) # vetor com 10 elementos, todos iguais a 1## [1] 1 1 1 1 1 1 1 1 1 1rep(c(1, 2), 5) # vetor com 10 elementos, c(1, 2) repetidos 5 vezes## [1] 1 2 1 2 1 2 1 2 1 2rep(c(1, 2), each = 5) # vetor com 10 elementos, 1 repetido 5 vezes, 2 repetido 5 vezes## [1] 1 1 1 1 1 2 2 2 2 21:10 # vetor de 1 a 10## [1] 1 2 3 4 5 6 7 8 9 1010:1 # vetor de 10 a 1## [1] 10 9 8 7 6 5 4 3 2 1numeric(10) # vetor com 10 elementos## [1] 0 0 0 0 0 0 0 0 0 0x <- c(1, 2)
y <- c(x, 3)
y # vetor com tres elementos## [1] 1 2 3x <- c(1, 2)
y <- c(1, 2)
z <- c(x, y, 1, 2) # vetor com seis elementos
z <- c(z, z) # vetor com 12 elementos
w <- rnorm(10) # vetor com 10 elementos gerados aleatoriamente (distribuição normal, média 0)Para saber o tamanho ou a classe de um vetor, usamos length e class (que já vimos).
x <- 1:100
length(x) # número de elementos de x## [1] 100class(x) # classe de x (integer)## [1] "integer"tamanho_x <- length(x) # salva o tamanho de x num novo objeto3.2 Indexação
Acessamos um ou mais elementos de um vetor com []. O jeito mais fácil de fazer isto é passar a posição do elemento para dentro dos colchetes.
x <- c(1, 5, 10, 15, 20)
x## [1] 1 5 10 15 20x[1] # acessa o primeiro elemento do vetor## [1] 1x[3] # acessa o terceiro elemento do vetor## [1] 10x[1 + 1] # acessa o segundo elemento do vetor## [1] 5x[length(x)] # acessa o último elemento do vetor## [1] 20x[c(1, 2)] # acessa o primeiro e o segundo elementos do vetor## [1] 1 5x[c(1, 3, length(x))] # acessa o primeiro, o terceiro e o último elementos do vetor## [1] 1 10 20x[-2] # acessa todos os elementos do vetor, menos o segundo## [1] 1 10 15 20x[-c(1, 2)] # acessa todos os elementos do vetor, menos o primeiro e o segundo## [1] 10 15 20Outro jeito, mais prático em algumas situações, é passar um vetor com valores lógicos de mesmo tamanho do vetor original para dentro dos colchetes.
x <- c(1, 2, 3)
x## [1] 1 2 3x[c(TRUE, FALSE, FALSE)] # acessa o primeiro elemento## [1] 1x[c(FALSE, TRUE, FALSE)] # acessa o segundo elemento## [1] 2x[c(T, F, T)] # acessa o primeiro e o último elementos## [1] 1 3Combinando operadores relacionais e vetores, podemos selecionar elementos de acordo com algum critério (como acessar apenas elementos maiores que 2).
x <- c(1, 2, 3, 4, 5)
x## [1] 1 2 3 4 5x > 3## [1] FALSE FALSE FALSE TRUE TRUEx[x > 3] # acessa apenas elementos maiores que 3## [1] 4 5x[x == 2] # acessa apenas elementos iguais a 2## [1] 2x[x == 1 | x == 5] # acessa apenas elementos iguais a 1 ou elementos iguais a 5## [1] 1 5x[x > 2 & x < 4] # acessa apenas elementos maiores que 2 e menores que 4## [1] 3x[x != 3] # acessa apenas elementos diferentes de 3## [1] 1 2 4 5O mesmo vale para vetores com character.
vec <- c("a", "c", "e")
vec## [1] "a" "c" "e"vec[vec == "a"] # acessa apenas elementos iguais a "a"## [1] "a"vec[vec != "c"] # acessa apenas elementos diferentes de "c"## [1] "a" "e"3.3 Manipulação de vetores
Sabendo como criar objetos e indexar vetores, combinamos as duas coisas para modificar e realizar operações com vetores. Um exemplo: alterar o valor do primeiro elemento de um vetor.
x <- 1:5
x[1] <- 99 # muda o valor do primeiro elemento do vetor para 99
x## [1] 99 2 3 4 5x[c(1, 2)] <- c(99, 100) # muda o valor do primeiro e do segundo elementos do vetorMas também podemos modificar elementos baseados numa condição (operadores relacionais novamente).
x <- 1:10
x[x < 5] <- 99
x## [1] 99 99 99 99 5 6 7 8 9 10y <- letters[1:5]
y[y == "a"] <- "X"
y## [1] "X" "b" "c" "d" "e"z <- rnorm(100)
z[z > 0 & z < 1] <- 99
z## [1] 1.51178117 99.00000000 -0.62124058 -2.21469989 1.12493092
## [6] -0.04493361 -0.01619026 99.00000000 99.00000000 99.00000000
## [11] 99.00000000 99.00000000 99.00000000 -1.98935170 99.00000000
## [16] -0.05612874 -0.15579551 -1.47075238 -0.47815006 99.00000000
## [21] 1.35867955 -0.10278773 99.00000000 -0.05380504 -1.37705956
## [26] -0.41499456 -0.39428995 -0.05931340 1.10002537 99.00000000
## [31] -0.16452360 -0.25336168 99.00000000 99.00000000 -0.68875569
## [36] -0.70749516 99.00000000 99.00000000 -0.11234621 99.00000000
## [41] 99.00000000 -0.61202639 99.00000000 -1.12936310 1.43302370
## [46] 1.98039990 -0.36722148 -1.04413463 99.00000000 -0.13505460
## [51] 2.40161776 -0.03924000 99.00000000 99.00000000 -0.74327321
## [56] 99.00000000 -1.80495863 1.46555486 99.00000000 2.17261167
## [61] 99.00000000 -0.70994643 99.00000000 -0.93409763 -1.25363340
## [66] 99.00000000 -0.44329187 99.00000000 99.00000000 -0.58952095
## [71] -0.56866873 -0.13517862 1.17808700 -1.52356680 99.00000000
## [76] 99.00000000 1.06309984 -0.30418392 99.00000000 99.00000000
## [81] -0.54252003 1.20786781 1.16040262 99.00000000 1.58683345
## [86] 99.00000000 -1.27659221 -0.57326541 -1.22461261 -0.47340064
## [91] -0.62036668 99.00000000 -0.91092165 99.00000000 -0.65458464
## [96] 1.76728727 99.00000000 99.00000000 99.00000000 1.68217608Partindo destas operações mais simples, podemos criar condições mais complexas - como transformar apenas números pares em 0.
x <- 1:100
x[x %% 2 == 0] <- 0 # número maior que 0 que seja divisível por 2 sem resto é par
x## [1] 1 0 3 0 5 0 7 0 9 0 11 0 13 0 15 0 17 0 19 0 21 0 23
## [24] 0 25 0 27 0 29 0 31 0 33 0 35 0 37 0 39 0 41 0 43 0 45 0
## [47] 47 0 49 0 51 0 53 0 55 0 57 0 59 0 61 0 63 0 65 0 67 0 69
## [70] 0 71 0 73 0 75 0 77 0 79 0 81 0 83 0 85 0 87 0 89 0 91 0
## [93] 93 0 95 0 97 0 99 03.4 Conversão de vetores
Vetores não armazenam informações de diferentes classes - ao fim, elas são transformadas para uma das classes existentes. Teste variações dos exemplos abaixo para entender como o R força essas conversões.
x <- c(1, "a")
x # o número 1 vira texto "1"## [1] "1" "a"class(x) # character## [1] "character"x <- c(1, TRUE, FALSE)
x # TRUE é convertido para 1; FALSE é convertido para 0## [1] 1 1 0class(x) # numeric## [1] "numeric"x <- c(1L, 2.3)
x # 1L (integer) é convertido para decimal (numeric)## [1] 1.0 2.3class(x) # numeric## [1] "numeric"x <- c(TRUE, "a")
x # TRUE vira texto "TRUE"## [1] "TRUE" "a"class(x) # character## [1] "character"Resumindo a conversão de classes básicas:
charactertem precedência sobre as outras classes;logicalpode ser convertido paranumeric;integerpode ser convertido paranumeric(ganha casas decimais).
No R, existem algumas funções para converter explicitamente um classe em outra. Seguem algumas.
x <- c(1.1, 2.2, 3.3, 4.4, 5.5)
class(x) # numeric## [1] "numeric"x <- as.integer(x)
x## [1] 1 2 3 4 5class(x) # agora é integer## [1] "integer"x <- as.character(x)
x## [1] "1" "2" "3" "4" "5"class(x) # agora é character## [1] "character"x <- as.numeric(x) # converte de character para numeric
x## [1] 1 2 3 4 5class(x)## [1] "numeric"x <- as.integer(x) # converte de numeric para integer
class(x)## [1] "integer"x <- as.logical(x) # converte x para logical (tudo o que for diferente de 0 vira TRUE)
x## [1] TRUE TRUE TRUE TRUE TRUEclass(x)## [1] "logical"Ainda assim, não podemos fazer conversões como esta.
x <- c("Texto")
as.numeric(x)## Warning: NAs introduzidos por coerção## [1] NANeste caso, x vira NA, que é valor logical especial no R para representar missings (valores ausentes). Como o NA, o R também possui alguns valores especiais. Vamos vê-los na sequência.
3.5 Valores especiais
Como dito anteriormente, NA é um valor logical particular, e serve para indicar missings. Mas, apesar de ser logical (TRUE ou FALSE), ele não muda a classe de um vetor de outro tipo. Exemplo.
x <- NA
class(x) # NA é logical## [1] "logical"class(NA) # NA é logical## [1] "logical"x <- c(1, 2, 3, NA)
class(x) # mas 'x' é numeric## [1] "numeric"z <- c("a", "b", NA)
class(z) # e z é character## [1] "character"class(z[3]) # assim como o terceiro elemento de z, que armazena o NA## [1] "character"Basicamente, isto significa que o NA pode ser convertido para qualquer classe a partir de logical e que, no fundo, ele serve para dizer o seguinte: o R não sabe qual valor NA deve assumir, mas certamente é um valor da mesma classe do restante do vetor (afinal, todos os elementos de um vetor precisam ser da mesma classe).
x <- NA
x <- as.integer(NA)
class(x) # NA agora é integer## [1] "integer"x <- NA
x <- as.character(NA)
class(x) # NA agora é character## [1] "character"Podemos testar se um valor ou objeto é NA com a função is.na (este é o método mais apropriado de fazer isto, por sinal).
x <- c(1, 2, NA)
is.na(x[3]) # como testar se um valor é NA## [1] TRUEx[3] == NA # como NÃO testar se um valor é NA## [1] NANote também que qualquer operação feita num objeto NA retorna NA (às vezes também dá erro).
NA + 1## [1] NANA / 2## [1] NAOutros valores especiais são Inf, para positivo e negativo infinito, e NaN, que literalmente significa “não é um número” (not a number). Exemplos.
# Exemplos de números infinitos
Inf + 1## [1] Inf-Inf + 1## [1] -Inf1 / 0## [1] Infx <- Inf
class(x) # infinito é numeric## [1] "numeric"is.infinite(x) # mas infinito## [1] TRUE# Exemplos de not a number
log(-2) # não existe log de números negativos## Warning in log(-2): NaNs produzidos## [1] NaN0 / 0## [1] NaNx <- NaN
class(x) # NaN também é numeric## [1] "numeric"is.nan(x)## [1] TRUEOutro valor, este não tão comum (a depender da aplicação): o NULL, que indica um objeto nulo, ou vazio, sem classe e sem valores.
class(NULL) # classe "NULL"## [1] "NULL"NULL + 1 # vira NULL## numeric(0)c(1, 2, 3, NULL) # desaparece do fim do vetor## [1] 1 2 3is.null(NULL) # maneira de testar se um objeto é NULL## [1] TRUEComo um objeto NULL, por definição, é vazio, podemos usar este valor especial para apagar o conteúdo de objetos de outras classes.
x <- c(1, 2, 3)
x <- NULL
x # apaga o vetor x## NULLMas perceba que isto não funciona para apagar elementos dentro de um vetor. Para remover um objeto da memória no R, contudo, usamos a função rm - é só passar para ela o nome do objeto que queremos remover.
x <- c(1, 2, 3)
rm(x)É importante reconhecer estes valores especiais para, se preciso, podermos alterá-los: como quando precisamos transformar missings em outras coisas.
x <- c(2, 5.6, 24, 45, 89.23, NA)
is.na(x)## [1] FALSE FALSE FALSE FALSE FALSE TRUEx[is.na(x)] <- 999 # trocamos o NA por 999
x## [1] 2.00 5.60 24.00 45.00 89.23 999.004 Estatística básica
Vetores numéricos ou inteiros armazenam números que podem ser analisados estatisticamente. E, para tanto, o R oferece um conjunto de funções nativas para realizar as mais diversas análises e testes.
Vimos funções anteriormente, mas cabe lembrar que elas (como funções na matemática) recebem uma informação (no R, geralmente um objeto) e retornam outra. Dá para saber se um objeto é uma função pelas funções class e is.function.
class(mean) # mean() é uma função## [1] "function"is.function(mean)## [1] TRUEclass(class) # assim como a própria função class() é uma função## [1] "function"is.function(class)## [1] TRUEis.function(is.function) # ou como is.function() é uma função## [1] TRUEAlgumas das estatísticas descritivas mais usadas.
# Criamos um vetor aleatoriamente com distribuição normal e média 0
x <- rnorm(100)
mean(x) # média de x## [1] -0.01984126median(x) # mediana de x## [1] -0.1679293weighted.mean(x, x) # média ponderada (o segundo x deve ser um vetor com os pesos)## [1] -50.3858sd(x) # desvio-padrão de x## [1] 1.004698max(x) # máxima de x## [1] 2.497662min(x) # mínima de x## [1] -2.285236quantile(x) # quantis de x## 0% 25% 50% 75% 100%
## -2.2852355 -0.6394764 -0.1679293 0.5236411 2.4976616summary(x) # retorna várias estatísticas básicas de uma só vez## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -2.28500 -0.63950 -0.16790 -0.01984 0.52360 2.498004.1 Aninhando funções
Às vezes, uma forma prática de usar funções é aninhando elas, isto é, passando uma função para dentro de outra. Exemplo.
mean(seq(1, 10))## [1] 5.5Como dá para intuir, seq(1, 10) cria um vetor de 1 a 10 e, diretamente, este vetor é passado para dentro da função mean - sem a necessidade de salvar o resultado de seq(1, 10) num objeto para, então, passá-lo para a função mean.
Este uso aninhado de funções pode ir além.
c(1, 2, c(1, 2, c(1, 2, c(1, 2, c(1, 2, c(1, 2))))))## [1] 1 2 1 2 1 2 1 2 1 2 1 2Mas, à medida que vamos aninhando funções, fica mais difícil entender o código. É por esta razão, principalmente, que o aninhamento de funções é melhor usado apenas em tarefas mais simples.
4.2 Argumentos opcionais
A maioria das funções no R-base possui argumentos opcionais que podem ser alterarados para atender a alguma necessidade. Geralmente, passamos estes argumentos para dentro das funções via =, como abaixo.
x <- c(1, 2, 3, 4, NA)
mean(x) # retorna NA## [1] NAmean(x, na.rm = TRUE) # na.rm = TRUE para ignorar os NA## [1] 2.5O uso de cada função, com a documentação completa dos argumentos opcionais, pode ser visto com via função help: basta passar o nome da função desejada para ela.
help(mean)5 Gráficos
5.1 Histogramas
O R também possui um potente arsenal nativo de implementações gráficas. Como no caso das estatísticas básicas, acessamos estas ferramentais via funções. Podemos começar com uma das mais simples: o histograma.
x <- rnorm(100) # cria um vetor
hist(x) # a função hist() cria um histograma
A função hist, assim como as demais funções gráficas nativas do R, possui diversos argumentos opcionais que nos permitem controlar a aparência do gráfico.
Incluímos títulos e mudamos o nome dos eixos com os argumentos main, xlab e ylab, respectivamente.
hist(x, main = "Um histograma", xlab = "Eixo X", ylab = "Eixo Y")
Mudamos a cor das barras com col.
hist(x, main = "Um histograma", xlab = "Eixo X", ylab = "Eixo Y", col = "red")
E a espessura das barras (i.e., o número de elementos por barra) com breaks.
hist(x, main = "Um histograma", xlab = "Eixo X", ylab = "Eixo Y", col = "red", breaks = 50)
Para organizar melhor o código, podemos quebrá-lo em linhas - nada mudará na sua execução, mas fica visualmente mais simples de entender o que estamos fazendo.
hist(x, main = "Um histograma",
xlab = "Eixo X",
ylab = "Eixo Y",
col = "red",
breaks = 50)5.2 Scatterplots
Para visualizar relações bivariadas, o gráfico de pontos (scatterplot) geralmente é a melhor opção. Criamos ele com a função plot.
x <- rnorm(100)
y <- rnorm(100)
plot(y ~ x)
# plot(x, y) é a mesma coisaTambém podemos alterar uma série de elementos do gráfico. Vamos, novamente, mudar títulos e cores.
plot(y ~ x, main = "Um scatterplot",
xlab = "Eixo X",
ylab = "Eixo Y",
col = "red")
Ainda podemos alterar o formato dos eixos - deixando-os abertos, por exemplo.
plot(y ~ x, main = "Um scatterplot",
xlab = "Eixo X",
ylab = "Eixo Y",
col = "red",
bty = "n")
E depois mudar o formato dos pontos.
plot(y ~ x, main = "Um scatterplot",
xlab = "Eixo X",
ylab = "Eixo Y",
col = "red",
bty = "n",
pch = 2) # pch muda o formato dos pontos
Os valores mais comuns de pch são (veja outros aqui):
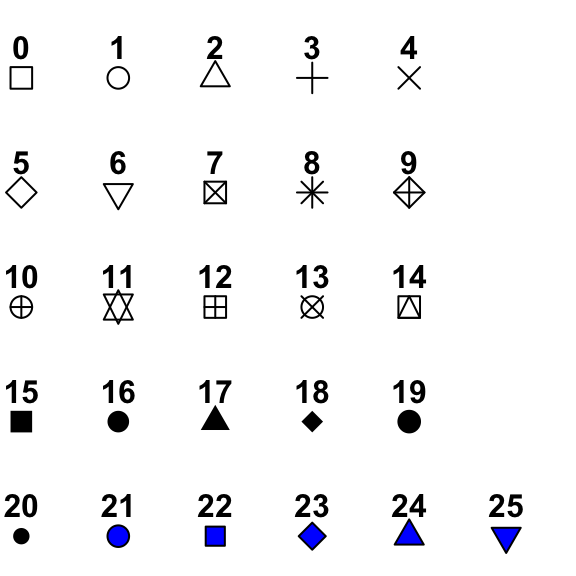{kind=link}
0, para quadrado vazado;1, para círculo vazado;2, para triângulo vazado;16, para círculo pequeno sólido;19, para círulo grande sólido.
5.3 Line plots
Gráficos de linhas, frequentemente usados para plotar séries temporais, também são criados com a função plot.
x <- 1:20
y <- rnorm(20)
plot(y ~ x, type = "l")
Uma vez que o gráfico esteja criado, podemos adicionar novas linhas a ele com a função lines.
x <- 1:20
y <- rnorm(20)
plot(y ~ x, type = "l")
z <- rnorm(20)
lines(z, col = "red")
5.4 Pontos e linhas
Para combinar pontos e linhas, basta usar o argumento opcional type = "b".
x <- 1:20
y <- rnorm(20)
plot(y ~ x, type = "b")
5.5 Boxplot
Em algumas situações, precisamos plotar a distribuição de uma variável por grupos: por exemplo, queremos saber a distribuição da nota dos(as) alunos(as) de duas escolas diferentes. Aqui vai um exemplo de como criar um boxplot mais simples, primeiro.
# Boxplot com uma só variável
x <- rnorm(100)
boxplot(x)
Agora um exemplo por grupos (precisamos de um vetor que indique quais são estes grupos).
x <- rnorm(100)
grupos <- rep(c("Grupo A", "Grupo B"), each = 50)
boxplot(x ~ grupos, main = "Um boxplot")
5.6 Gráficos de barras
Por fim, vamos ver como criar gráficos de barras - aqueles gráficos onde cada grupo no eixo X é representado por uma barra indicando o valor dela no eixo Y. Para criar estes gráficos, usamos duas funções combinadas: table, para criar uma tabela de frequência, e plot ou barplot, para plotar o gráfico.
grupoA <- rep("Grupo A", 30)
grupoB <- rep("Grupo B", 20)
grupoC <- rep("GrupoC", 9)
grupos <- c(grupoA, grupoB, grupoC)
grupos <- table(grupos) # table cria uma tabela de frequência
grupos## grupos
## Grupo A Grupo B GrupoC
## 30 20 9plot(grupos) # cria uma gráfico de barras com plot
barplot(grupos) # cria um gráfico de barras com barplot
5.7 Mais gráficos
O R-base possui muitas outras opções de gráficos e de funções que, entre outros, nos permitem fazer gráficos como este.

Para saber mais sobre gráficos no R-base, um bom guia pode ser visto aqui. Também use a função help para obter ajuda sobre argumentos opcionais de cada função.
6 Regressão linear
Regressões nos ajudam a entender a relação entre uma variável quantitativa e uma ou mais variáveis explicativas. E o modelo mais usado para realizar este tipo de análise, sem dúvidas, é a regressão linear, que modela a relação entre variáveis dependente e independente de forma linear - a reta que melhor se ajusta aos dados. No R, podemos estimar regressões como estas com a função lm, de linear model.
6.1 Modelo bivariado
Vamos começar com um exemplo simples: modelar a relação entre dois vetores numéricos.
x <- rnorm(50)
y <- rnorm(50)
modelo <- lm(y ~ x) # estima um modelo linear e salva os resultados no objeto 'modelo'
class(modelo) # a classe do objeto 'modelo' vira 'lm'## [1] "lm"summary(modelo) # usamos a função 'summary' para exibir os resultados##
## Call:
## lm(formula = y ~ x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.40061 -0.66567 0.07957 0.52041 2.99862
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.0314 0.1501 0.209 0.835
## x 0.1527 0.1315 1.161 0.252
##
## Residual standard error: 1.061 on 48 degrees of freedom
## Multiple R-squared: 0.0273, Adjusted R-squared: 0.007035
## F-statistic: 1.347 on 1 and 48 DF, p-value: 0.2515O output da função summary nos dá um panorama geral dos resultados do modelo. Em ordem:
Call, no topo, indica a fórmula que passamos para o modelo;Residualsmostra a distribuição dos resíduos;Coefficientesreporta as estimativas do modelo:Estimatereporta os coeficientes;Std. Errorreporta erros-padrão;t valuereporta t valores;Pr(>|t|)reporta p-valores.
Residual standard error,Multiple R-squared,Adjusted R-squaredeF-statisticmostram algumas estatísticas de ajustes do modelo.
Usando a função plot vista anteriormente, podemos plotar a reta estimada nos dados originais.
plot(y ~ x, main = "Regressão linear")
abline(modelo) # a função abline toma um objeto 'lm' e plota a reta da regressão
Também podemos usar a função plot para termos uma noção geral do ajuste de um modelo.
plot(modelo)



6.2 Modelo multivariado
Modelos lineares podem ter mais de uma variável independente. Usamos a mesma função, lm, para fazer isto - a única coisa que modificamos é a fórmula passada ao modelo.
x <- rnorm(50)
z <- rnorm(50)
y <- rnorm(50)
modelo <- lm(y ~ x + z) # adicionamos variável com o operador '+'
summary(modelo)##
## Call:
## lm(formula = y ~ x + z)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.78551 -0.60214 -0.04739 0.60877 1.91859
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.15088 0.13230 -1.140 0.260
## x 0.19177 0.12861 1.491 0.143
## z -0.05275 0.12011 -0.439 0.663
##
## Residual standard error: 0.9347 on 47 degrees of freedom
## Multiple R-squared: 0.0471, Adjusted R-squared: 0.006552
## F-statistic: 1.162 on 2 and 47 DF, p-value: 0.3218Com mais de duas variáveis independentes no modelo, visualizar a relação entre elas e a variável dependente não é tão simples: o efeito de x e z são controlados por z e x, respectivamente. O que podemos fazer é ver o efeito parcial de cada preditor com a função termplot. (Na verdade, existem várias outras maneiras de fazer isto, mas a maioria delas pressupõe conhecimentos adicionais de R; uma boa referência pode ser vista aqui).
termplot(modelo)

6.3 Modelo com dummies
Em algumas situações, a relação linear entre duas variáveis pode ser diferente para grupos diferentes. Nestes casos, adicionar uma variável ao modelo indicando estes grupos pode ser uma boa opção.
x <- rnorm(100)
grupo <- rbinom(100, 1, prob = 0.5) # 'rbinom' serve para criar uma variavel com distribuicao binomial
y <- rnorm(100) + grupo # adicionando 'grupo', 'y' sera' afetada por ela
modelo <- lm(y ~ x + grupo)
summary(modelo)##
## Call:
## lm(formula = y ~ x + grupo)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.27228 -0.62717 -0.02431 0.63295 2.37059
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.2996 0.1495 2.003 0.04794 *
## x -0.1147 0.1051 -1.091 0.27810
## grupo 0.6659 0.2121 3.140 0.00224 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.057 on 97 degrees of freedom
## Multiple R-squared: 0.107, Adjusted R-squared: 0.08857
## F-statistic: 5.81 on 2 and 97 DF, p-value: 0.004137O output de summary já nos indica que a variável grupo tem efeito preditivo significativo sobre y. Com a função plot, podemos ter uma noção visual mais clara disto (usaremos a função points, que, assim como lines, serve para plotar pontos após um gráfico já ter sido criado).
plot(y ~ x, type = "n") # 'type = n' plota apenas os eixos do gráfico
points(y[grupo == 1] ~ x[grupo == 1], col = "red")
points(y[grupo == 0] ~ x[grupo == 0], col = "blue")
É possível perceber pelo gráfico que as observações em vermelho (grupo == 1) tendem a ter maiores valores no eixo Y. O que vamos fazer, agora, é plotar uma reta de regressão para cada grupo, tomando nosso modelo para fazer isto.
Usaremos a função fitted para salvar os valores preditos do modelo e, com isto, plotaremos as retas usando a função lines (este exemplo pode parecer complicado, mas envolve apenas coisas que já vimos anteriormente; se tiver dúvidas, tente refazer este exemplo de outras maneiras, até entender).
plot(y ~ x, type = "n", main = "Regressão com dummy")
points(y[grupo == 1] ~ x[grupo == 1], col = "red") # p
points(y[grupo == 0] ~ x[grupo == 0], col = "blue")
lines(x[grupo == 1], fitted(modelo)[grupo == 1], col = "red")
lines(x[grupo == 0], fitted(modelo)[grupo == 0], col = "blue")
6.4 Termos multiplicativos
O exemplo anterior mostra como estimar uma reta para cada grupo num modelo linear, todas com a mesma inclinação. Podemos relaxar isto utilizando termos multiplicativos (x * grupo) para fazer com que cada reta se ajuste individualmente ao grupo de dados. Novamente, só modificamos a fórmula passada para a função lm para fazer isto.
modelo <- lm(y ~ x * grupo) # reestimamos o modelo com o termo multiplicativo
# Criamos novamente o gráfico
plot(y ~ x, type = "n", main = "Regressão com termo multiplicativo")
points(y[grupo == 1] ~ x[grupo == 1], col = "red")
points(y[grupo == 0] ~ x[grupo == 0], col = "blue")
lines(x[grupo == 1], fitted(modelo)[grupo == 1], col = "red")
lines(x[grupo == 0], fitted(modelo)[grupo == 0], col = "blue")
6.5 Relação quadrática
Relações entre duas variáveis nem sempre são apenas lineares: às vezes, elas assumem algum tipo de curva. Ainda que um modelo linear nem sempre seja a melhor opção para modelar relações como estas, podemos adaptá-lo para dar conta disto. A solução, neste caso, é bem simples: passamos a variável independente ao quadrado para a função lm.
x <- rnorm(100)
x2 <- x^2
y <- x2 + rnorm(100) # adicionando 'x2' a 'y', fazemos com que a relação entre eles seja quadrática
plot(y ~ x, main = "Relação quadrática")
Só precisamos passar x e x2 para a fórmula na função lm para estimarmos a relação quadrática. Depois, para criarmos o gráfico, precisaremos criar dois novos vetores: 1) novo_x, que será um vetor sequencial contendo os valores máximos e mínimos de x como referências; e, 2), pred, que criaremos usando a função predict, que serve para usar um modelo que já estimamos para fazer predições em cima de novos dados (também usaremos a função list para passar x e x2 para dentro da função simultaneamente).
modelo <- lm(y ~ x + x2)
plot(y ~ x, main = "Relação quadrática")
novo_x <- seq(min(x), max(x), by = 0.1)
pred <- predict(modelo, list(x = novo_x, x2 = novo_x^2))
lines(novo_x, pred)
O mesmo procedimento também serve para uma relação cúbica.
x <- rnorm(100)
x2 <- x^2
x3 <- x^3
y <- x3 + rnorm(100)
modelo <- lm(y ~ x + x2 + x3)
plot(y ~ x, main = "Relação cúbica")
novo_x <- seq(min(x), max(x), by = 0.1)
pred <- predict(modelo, list(x = novo_x, x2 = novo_x^2, x3 = novo_x^3))
lines(novo_x, pred)
7 Mais
Este é o básico do R. Obviamente, mal tocamos na superfície das coisas que ele é capaz de fazer. Não trabalhamos, entre outros, com bancos de dados (data.frames), listas, controle de fluxo e nem com códigos desenvolvidos por outras pessoas - o que expande massivamente as possibilidades de uso do R. Algumas boas fontes sobre estas e outras coisas incluem:
Introdutórios
Documentação e manuais
7.1 Licença
Se precisar citar este material, use:
MEIRELES, F. (2017). R: Um guia prático. URL: http://fmeireles.com/teaching/r_um_guia_pratico.html.
