Aula 2
Introdução à Ciência de Dados e Revisão de Programação
Introdução
Esta aula cobre as diferenças entre aprendizado de máquia, ou aprendizagem estatística, e outras abordagens de análise de dados. Para quem está habituado a pensar em inferência e propriedades de estimadores, o que veremos é um pouco diferente: nosso objetivo, pelo menos na maioria das nossas aplicações, será predição. A diferença importa e tem a ver, essencialmente, com o tipo de pergunta que poderemos responder.
Predição vs. inferência
Existem várias definições que poderíamos usar, mas a distinção entre predição e inferência oferica no ITSL é útil. Considere um exemplo hipotético: sabemos quanto candidaturas gastaram em uma eleição, \(X_{i}\), e quantos votos obtiveram, \(Y_{i}\); com essas informações, poderíamos estimar um modelo como \(Y_{i} = \beta X_{i} + \epsilon_{i}\). O resultado do modelo estimado nos permitiria, por exemplo, avaliar se o gasto de campanha tem efeito positivo sobre votos, ou para fazer um chute embasado sobre o desempenho de uma candidatura no futuro. No primeiro caso, queremos inferir sobre o processo que deu origem aos dados; no segundo, predizer uma nova ocorrência.
Alguns exemplos de problemas de inferência:
Examinar se a iluminação pública tem relação com assaltos em São Paulo
Descobrir quanto um carro desvaloriza com um ano a mais de uso
Saber se pessoas com ensino superior ganham mais do que as demais
Alguns exemplos de problemas de predição:
A partir de exemplos de um texto de spam, identificar se um texto qualquer é ou não spam
Usar dados fiscas dos municípios para predizer a votação de uma candidatura específica à reeleição
Oferecer uma sugestão de filme baseada no histórico de usos na Netflix
Aprendizado de máquina
Não é algo diretamente relacionado ao conteúdo que iremos praticar nessa aula, mas é importante termos uma ideia do que significa aprendizado de máquina para nos situarmos. Sabendo que predição e inferência são coisas distintas, a tarefa fica mais simples.
De forma geral, apredizando de máquina engloba um conjunto de algoritmos e ferramentas que aprendem a generalizar padrões a partir de dados. Há várias definições similares:
The field of machine learning is concerned with the question of how to construct computer programs that automatically improve with experience – Mitchell e Mitchell (1997)
Machine learning (ML) is the process of using mathematical models of data to help a computer learn without direct instruction – Microsoft
Machine Learning is about making machines get better at some task by learning from data, instead of having to explicitly code rules – HML, p. 31
Trata-se, portanto, de uma área em que algoritmos descobrem o melhor modelo para relacionar preditores e variáveis dependentes (ou targets, terminologia comum em Ciência de Dados). Voltando ao nosso exemplo hipotético sobre gasto de campanha e votos, aprendizado de máquina é uma forma de encontrar a melhor função, \(f\), que relaciona gasto a votos:
\[ Y_{i} = f(X_{i})+ \epsilon_{i} \]
Como Grimmer, Roberts, e Stewart (2021) dizem no paper relacionado para esta aula, aprendizado de máquina é,em certo sentido, uma cultura: assume-se que não sabemos nada sobre \(f\) e que algoritmos podem aprender, sozinhos, a encontrar bons candidatos para o papel. Em outras palavras, aprendizado de máquina é um conjunto de métodos que automatiza o processo de encontrar funções com o objetivo de se fazer predição.
Academicamente, aprendizado de máquina é reconhecido como uma sub-área dos estudos sobre inteligência artificial, cujo objetivo, grosso modo, é desenvolver agentes que consigam tomar decisões e desenvolver estratégias para resolver diferentes problemas. Nesse sentido, aprendizado de máquina é parte relacionada ao aprendizado a partir dos dados que deve informar a tomada de decisões, mas há outras, como processamento de linguagem natural (NLP), por exemplo.
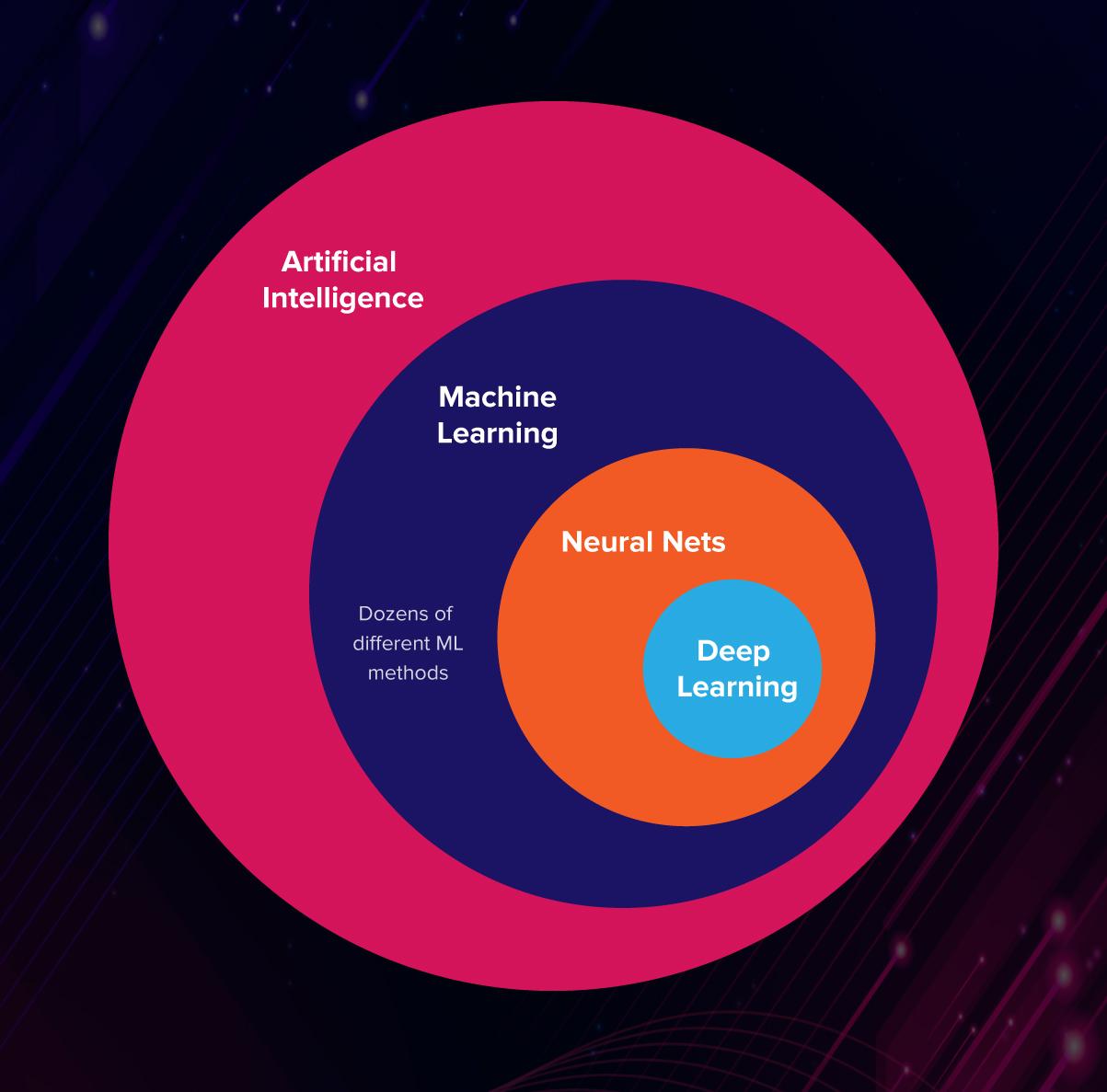
Tipos de problema
Dentro da área de aprendizado de máquina, há dois tipos principais de problemas de aprendizado1: supervisionado e não-supervisionado.
1 Há outros tipos de problemas, como os semi-supervisionados, self-supervised, ou ainda reinforcement learning, que não veremos neste curso.
O texto previsto do ITSL oferece boas definições para cada tipo de problema. Em termos práticos, no entando, é possível defini-los assim: 1) aprendizado supervisionado requer ter uma variável dependente e usá-la para aprender \(f\); 2) aprendizado não-supervisionado geralmente implica não ter a variável dependente para, a partir das variáveis independentes, se chegar em uma \(f\) que sirva para distinguir ou classificar diferentes observações (pense, por exemplo, em análise de cluster).
Entre problemas supervisionados, os mais comuns são o de regressão – que não devem ser confundidos com modelos de regressão –, no qual predizemos variáveis contínuas ou numéricas; e o de classificação, no qual predizemos a categoria a qual uma dada observação pertence. Essas distinções são úteis, como veremos, porque há algoritmos e estratégias de tuning e de validação apropriadas para cada tipo de problema de aprendizado.
Revisão de programação
Algo importante para avançar no curso é conseguir implementar controles de fluxo (for loops, mas também list compreension, em Python, e programação funcional com purrr, para quem usa R), manipular objetos (com o uso de métodos, no caso de quem estiver usando Python) e conseguir usar os principais frameworks de aprendizado de máquina.
Funções
Criar funções é algo extremamente útil para se automatizar determinadas rotinas. Neste curso, vamos usar, em alguns casos, funções específicas para facilitar o nosso trabalho. Caso tenha dúvidas, consulte este capítulo do R4DS ou este tutorial do Real Python.
Controle de fluxo
Usar loops é algo normalmente praticado em cursos básicos, mas, para quem tem dúvidas, vale consultar rapidamente essa este capítulo do R4DS, para quem usa R, e este tutorial do Real Python.
Frameworks
Vamos queimar várias etapas e ir logo para a aplicação dos frameworks. Nas próximas aulas, daremos vários passos atrás e cobriremos detidamente algoritmos e etapas de um projeto.
Tarefas
Em R, será necessário carregar o pacote mle3 e seguir este tutorial. Tente acompanhar o código e ir modificando ele para ver o que acontece (fique à vontade para usar outros modelos ou outros datasets, como o mtcars, que já vem por padrão no pacote datasets).
Em python, siga o getting started do Sci-kit learn, também brincando com o código. O exemplo, nesse caso, é mais complexo e cobre mais etapas de uma pipeline.